Hi all,
We are running a v20.10.0 and we have a couple of persistent subscriptions running on it. We have a couple of clients that connect to these. If a client goes does or the subscription is dropped, it would automatically reconnect once online again.
I see that some of our persistent subscriptions are have unusual connections to it, but only for some. I have verified multiple times and in all cases in our development environment there is just one client connecting to the subs.
I am wondering if there might be some objects that are not being disposed on ES? As if I recreate the persistent subscription the clients reconnect and then there is only one connection to the sub.
I see that there is still a port allocated in RESMON for it on Windows. So before restart we ES will have say for instance 50 ports allocated, but after the recreation of the persistent sub it will only have 30, usually the same number of ports are de-allocated as to the “Ghost Connections”
Any ideas?
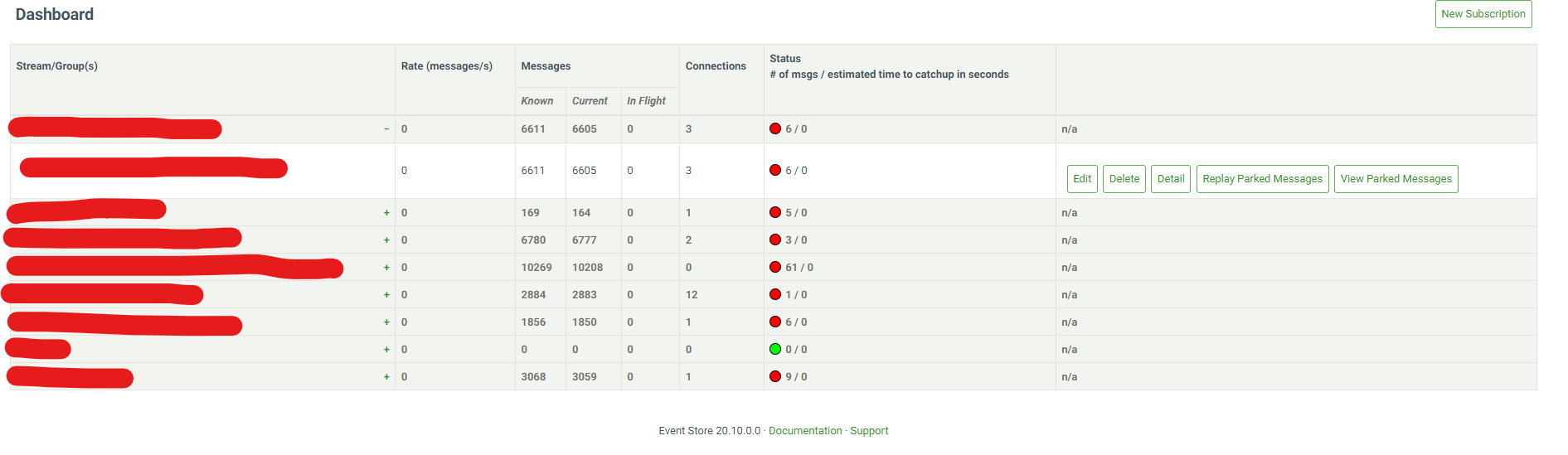
Image for clarification
The two streams that have 3 Connections and 12 connections. I have verified, we only have one client running and connecting to it.
what client are you using ( tcp or grpc + stack)
the (leader) server logs around the same time might provide some clue
We are using the grpc client on dotnet 5.
I will check if I can get the logs, it is currently still like that, so not sure from when I should pull the logs?
is that locally ?
from the moment you connect / disconnect some of the clients .
NB : the latest version in 20.10 is 20.10.4 & 20.10.5 will be shortly after 21.10.0
CAn you give it a try on 20.10.4 ?
No this is running on our development server. It is a one node cluster on dev.
I can unproivion the client and reprovion it again and then pull the logs. Would that help?
. Would that help?
Yes .
So you don’t have that on a single node , only on a multi-node?
No we have it on a single node. Have not deployed the code to the multinode due to this issue.
We cannot promote to production as it may affect the machines. As we already had port exhaustion on the development environment we are worried it might happen in production.
I cannot find anything else that is causing it, so that is the reason for my question here. Will get the logs now and post.
@theunis.vanderstoep, are you using any load balancer or reverse proxy? If yes, then if it’s not properly configurated, Keep Alives may cause the database to think there are open connections. See https://developers.eventstore.com/server/v20.10/networking/http.html#keepalive-pings.
1 Like
Hi, we are using a Service Fabric cluster with 7 Nodes that hosts our client applications.
Service Fabric would in some cases move an application from one node to another. We do dispose of the connection on graceful shutdown within the client application.
All of our clients are hosted in SF, so if this was the issue would we not be seeing it on all client applications?
Also @yves.lorphelin what is the exact logs that you are looking for? I have the following:
I see in the log_010 the connection that was created. I have checked now again. There is no other instance currently connected to the persistent sub except my local machine.
When I un-provision from my local machine I see the one connection drop, but it still shows the other three that are active, but there is definitely no code deployed anywhere that would be connecting currently.
log_010 & log-err should contain some information
Where can I post this, as it contains some data not meant for the entire world?
I will have a look at this, and report back ASAP
I think you have put me on the right path here. As our new developments all include the ServiceFabric.Remoting package, where previous did not include it, thus it seems that it might be this. Will still investigate this and see why this behavior is happening.
Will still provide the logs to @yves.lorphelin and see if that leads somewhere else.
cool , it will probably confirm it.
@oskar.dudycz I made a note to add this thing to the documentation , as others will probably also run into this
Can I send the logs to you personally to have a look at it?
Apologies, you are referring to the docs here? Are you referring to ES docs?
Also should I be setting the timeout on the persistent sub?
Thank you, missed that link completely.
My question now is, our ES is not behind a load balancer or reverse proxy, but our consuming applications are behind a load balancer, does the timeout then still have an effect?
I would assume not, so I expect that I would need to configure the client application on SF to have a different TCP keep alive and not on ES.?
Is my assumption correct?
Thanks for all the help. Highly appreciated.