Ok, so after a little break from investigating eventsourcing, I’m back with a little question.
From what i understand its preferred to version events per aggregate…
aggregate_id, version, data
1, 1, {…}
1, 2, {…}
2, 1, {…}
1, 3, {…}
Or maybe store it in sperate streams:
Stream 1:
1, 1, {…}
1, 2, {…}
1, 3, {…}
Stream 2:
2, 1, {…}
So if I want to make a projection, i keep track of it like:
id, current_version
1, 3
2, 1
correct?
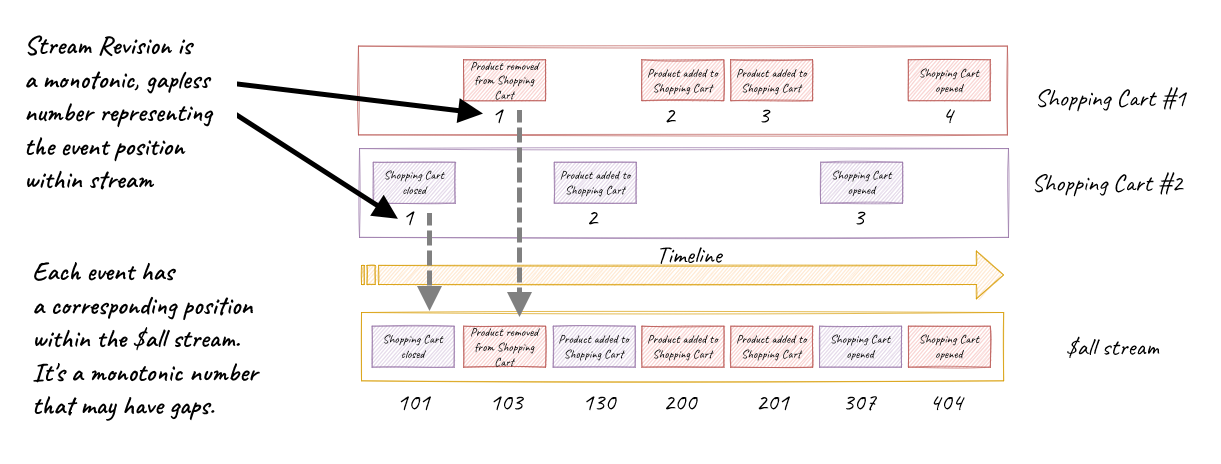
On the other hand the projections should always follow the complete stream? So why not version everything combined?:
version, aggregate_id, data
1, 1, {…}
2, 1, {…}
3, 2, {…}
4, 1, {…}
now the projections only need to remember it processed up to version 4?
 .
.