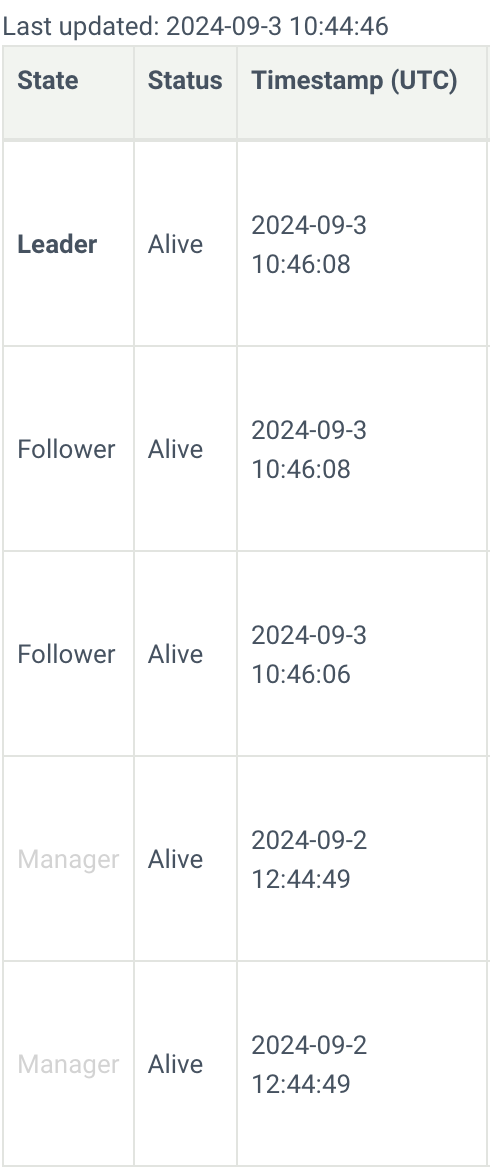
- I deployed an ESDB cluster using VMs with three nodes.
- In the configuration file, I used:
DiscoverViaDns: false
GossipAllowedDifferenceMs: 60000
GossipSeed: [Internal IP1]:2113,[Internal IP2]:2113
- NTP is installed on the VMs for time synchronization, and the status shows as normal.
- Version: 23.10.1
After deployment, it has been reporting errors continuously.
{"@t":"2024-09-02T06:11:50.8540669+00:00","@mt":"Time difference between us and [{peerEndPoint}] is too great! UTC now: {dateTime:yyyy-MM-dd HH:mm:ss.fff}, peer's time stamp: {peerTimestamp:yyyy-MM-dd HH:mm:ss.fff}.","@r":["2024-09-02 06:11:50.854","2024-09-02 05:56:29.134"],"@l":"Error","@i":1738112734,"peerEndPoint":"Unspecified/10.0.2.6:2113","dateTime":"2024-09-02T06:11:50.8540415Z","peerTimestamp":"2024-09-02T05:56:29.1343539Z","SourceContext":"EventStore.Core.Services.Gossip.GossipServiceBase","ProcessId":44831,"ThreadId":16}
{"@t":"2024-09-02T06:11:58.8664832+00:00","@mt":"Time difference between us and [{peerEndPoint}] is too great! UTC now: {dateTime:yyyy-MM-dd HH:mm:ss.fff}, peer's time stamp: {peerTimestamp:yyyy-MM-dd HH:mm:ss.fff}.","@r":["2024-09-02 06:11:58.866","2024-09-02 05:10:28.444"],"@l":"Error","@i":1738112734,"peerEndPoint":"Unspecified/10.0.2.7:2113","dateTime":"2024-09-02T06:11:58.8664658Z","peerTimestamp":"2024-09-02T05:10:28.4445972Z","SourceContext":"EventStore.Core.Services.Gossip.GossipServiceBase","ProcessId":44831,"ThreadId":16}
{"@t":"2024-09-02T06:12:00.8760705+00:00","@mt":"Time difference between us and [{peerEndPoint}] is too great! UTC now: {dateTime:yyyy-MM-dd HH:mm:ss.fff}, peer's time stamp: {peerTimestamp:yyyy-MM-dd HH:mm:ss.fff}.","@r":["2024-09-02 06:12:00.876","2024-09-02 05:10:28.444"],"@l":"Error","@i":1738112734,"peerEndPoint":"Unspecified/10.0.2.7:2113","dateTime":"2024-09-02T06:12:00.8760533Z","peerTimestamp":"2024-09-02T05:10:28.4445972Z","SourceContext":"EventStore.Core.Services.Gossip.GossipServiceBase","ProcessId":44831,"ThreadId":16}
{"@t":"2024-09-02T06:12:02.8766960+00:00","@mt":"Time difference between us and [{peerEndPoint}] is too great! UTC now: {dateTime:yyyy-MM-dd HH:mm:ss.fff}, peer's time stamp: {peerTimestamp:yyyy-MM-dd HH:mm:ss.fff}.","@r":["2024-09-02 06:12:02.876","2024-09-02 05:10:28.444"],"@l":"Error","@i":1738112734,"peerEndPoint":"Unspecified/10.0.2.7:2113","dateTime":"2024-09-02T06:12:02.8766800Z","peerTimestamp":"2024-09-02T05:10:28.4445972Z","SourceContext":"EventStore.Core.Services.Gossip.GossipServiceBase","ProcessId":44831,"ThreadId":16}
{"@t":"2024-09-02T06:12:04.8799389+00:00","@mt":"Time difference between us and [{peerEndPoint}] is too great! UTC now: {dateTime:yyyy-MM-dd HH:mm:ss.fff}, peer's time stamp: {peerTimestamp:yyyy-MM-dd HH:mm:ss.fff}.","@r":["2024-09-02 06:12:04.879","2024-09-02 05:56:29.134"],"@l":"Error","@i":1738112734,"peerEndPoint":"Unspecified/10.0.2.6:2113","dateTime":"2024-09-02T06:12:04.8799129Z","peerTimestamp":"2024-09-02T05:56:29.1343539Z","SourceContext":"EventStore.Core.Services.Gossip.GossipServiceBase","ProcessId":44831,"ThreadId":16}
What should I do? Please help me.
Thank you.