I have an existing application which I’m considering changing to use EventStoreDb as its event store. I’m planning to run some tests, but I thought I’d first ask here to see if people with more experience of EventStoreDb think it’s suitable for the use case. First: some key facts:
At any one time we need to store a relatively high number of streams. At least on the tens of thousands and potentially in the hundreds of thousands
Streams need to eventually expire. I.e after n days we need to be able to truncate them and reclaim any resources they take up. I see that EventStoreDb can do this but it keeps a marker around. I guess this means that if you subsequently try and create a new stream with the same name then it will fail? also I do wonder whether EventStoreDb will like it if there are millions of truncated streams which dwarf the number of live streams.
The number of messages on any given stream will vary greatly. The maximum number of messages on a stream will be in the single digit millions, but most will have a few thousand messages at most.
The sizes of each message should be relative small. A small percentage of messages will be kilobytes in size, but most will be in the tens to hundreds of bytes range.
The most important access pattern for read is to be able to efficiently retrieve all events from a stream- I.e. a catch up subscription starting from the beginning of the stream.
we may need to support hundreds or even thousands of concurrent readers.
I realise I’ve written a lot there but if anyone with experience wants to comment it would be much appreciated!
at any one time we need to store…
Not a problem , EventStoreDb is made for this
Streams need to eventually expire… after N days truncate…
you mean delete streams or truncate them ?
Truncation can be automatic ( though you will need to run scavenge to actually reclaim the space , this can be automated )
Truncation for ESDB means in that stream remove events older than X (some time span)
Deletion of stream is also an option, but not automatic you have to delete them it’s either a tombstone (the stream can not be recreated, or a delete where the stream can be recreated and the next appendend event will get the next revisions umber
The sizes of each message s
nothing to say here
The most important access pattern for read is to be able to efficiently retrieve all events from a stream- I.e. a
not seeing an issue there,
we may need to support hundreds or even thousands of concurrent readers.
that will be a good reason to test performance of the database, memory & IOPS mainly and the system as a whole
Hi,
Fine grained streams is one of the key features of Event Store.
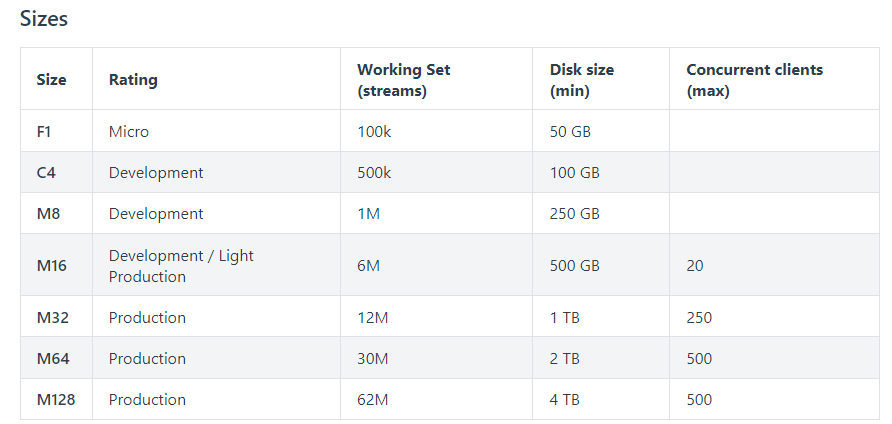
Here is a screen cap from our cloud sizing guide. Note the working set is the active number of streams in concurrent use. The total streams is expected to be higher.
Thanks,
Chris
What you describe is a hard delete. When you hard-delete a stream, ESDB will tombstone it with a special marker, as you said, so they won’t be recreated again. However, for archiving scenarios it’s not really what you’d do. You’d rather soft-delete the stream, potentially archiving its content to something like an S3 bucket. When you’d need to restore the stream from the archive, you’d just put all the events back. That’s the strategy we use in production. I think when a stream is soft-deleted, we still keep its metadata (which is an event) so when you write to the same stream again, it will keep the numbering from the last known event number, etc. It should not really affect the database performance though as the metadata event is very small.
Concerning long streams, our product fits more to the scenario where one event stream represents one entity. In such a case, streams with millions or even thousands of events usually indicate a design smell, as the entity boundaries are probably identified incorrectly, and that particular entity takes too much responsibility, so it needs to be split up. A common case is something that we can call Product, where things like product metadata, stock level changes due to both sales (decrease) and filling up stock (increase), are all in the same stream. I would never design a system like that as it has multiple contexts missed together, along with all the different responsibilities.
Also, you mention reading all the events from a stream in one line with catch-up subscriptions. In EventStoreDB these are two different use cases. You’d read a stream to reconstruct an entity state as all the events represent individual state transitions. You subscribe to a stream, which contains events ($all) or links (like $ce) from multiple streams to compose use case-specific read models (materialised views), and those subscriptions run continuously, forever, until the read model demand is gone, and it’s replaced with another one.