Hello Guys!
Currently, in my company, we are considering to adopt event store for some features that we are extracting from our core service and would be great if you could clarify some doubts.
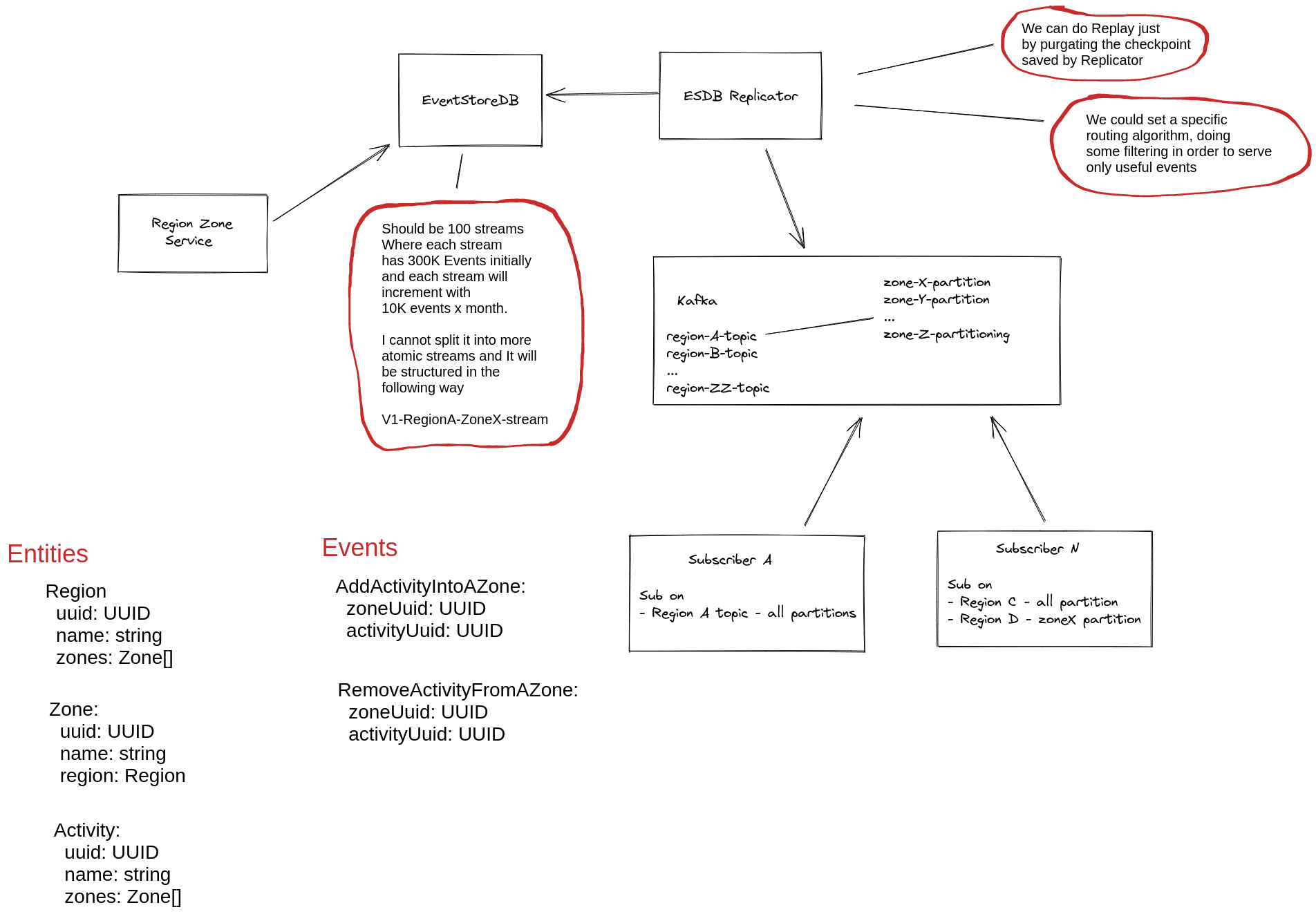
In a feature that we want to migrate we have three entities that are defined in the following way:
Region
uuid: UUID
name: string
zones: Zone[]
Zone:
uuid: UUID
name: string
region: Region
Activity:
uuid: UUID
name: string
zones: Zone[]
Where we have the possibilities to add an Activity to a Zone and a Zone could be assigned only to a Region.
Then, we will have the following events:
AddActivityIntoAZone:
zoneUuid: UUID
activityUuid: UUID
RemoveActivityFromAZone:
zoneUuid: UUID
activityUuid: UUID
We will have, more or less, 100 streams where each stream has between 20K - 300K events initially
and each stream will increment with 3 - 10K events x month.
I cannot split it into more atomic streams and It will be structured in the following way
V1-RegionA-ZoneX-stream
We are using Replicator and Kafka. The various topic will be consumed by different services and Kafka will have a forever retention policy to not flood the different services when some service need to replay all the events. We thought about this approach just to have a security that all the changes are correctly propagated and that would be easy to replay all the events in case of necessity.
I’m wondering if EventStoreDB could manage this kind of load in a long time span or if it is needed a stream reduction process (a sort of “Snapshotting”).
By stream reduction I’m intending on regroup events by creating a new stream that regroup all the events with a new type of event like:
AddMultipleActivityIntoAZone:
zoneUuid: UUID
activitiesUuid: UUID
RemoveMultipleActivityFromAZone:
zoneUuid: UUID
activitiesUuid: UUID[]
And the events that aren’t part of regrouping, will be appended immediately after. The old stream will be stored into a S3 bucket.
If is needed a stream reduction, I know that the projections on Replicator could be helpful. To respect the event orders, We need to create the reduced stream, stop the functionality for some time, appending the events that We’ve not reduced and restart the functionality.
Furthermore, We need to delete all old kafka topic and change stream name on Replicator.
Is there a better and/or native approach that simplify the resolution of this kind of problems?
If could be helpful, I’ve created a little architectural sketch.
Thank you in advance for any answer or feedback 
