Looks like you’re mostly there. The schedule is “something else” from the house. Then there is no set, just the schedule.
Kijana - now I’m a bit confused.
Resource/House is an entity in my system. Often it will act as an aggregate root (for example we can mark house as needs cleaning/cleaned.
Booking is an entity and an aggregate root for sure. I can cancel the booking, I can change what is booked and for how long.
…
I will now try to answer my own question coz I got an insight 
If Schedule is an aggregate. It can handle OrderResourceBooking command.
It would then both have the data in the event stream and also be responsible for validation.
If it accepts the command it can raise BookingAccepted event.
This in turn could be handled by Saga/ProcessManager to issue CreateBooking command.
In turn creating booking Aggregate
Booking Aggregate then raises BookingCreated - handled on the read side.
Picture attached.
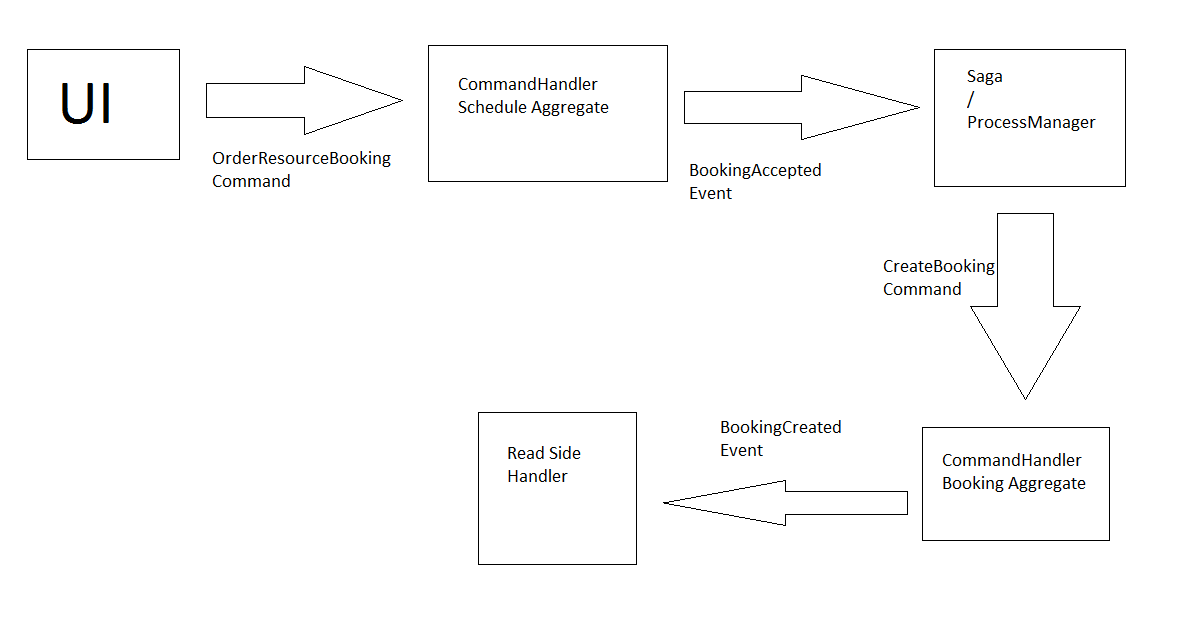
Makes sense?
Yes this would work perfectly well. It could also handle the case of a race condition as the actual booking would have one win and the other fail. Be careful how you order them though or you could have two both say they can’t do it (they share 2 bookings aka deadlock)
Just to confirm.
It is ok to have a Scheduler aggregate which has a purpose to store the state of which resource/house is booked when as opposed to having that state associated with those resources.
This is a very different approach from what I would normally use - and for this reason I need some assurance
disclaimer: no one’s gonna die if I get it wrong - it’s a learning exercise. I have a working and proven product already. I am expecting opinionated answers
Not sure if you would want one schedule it works well if you don’t have huge numbers of schedules or lots of tps.
I would see something like this. You have a schedule that is say for a given month or for a given contract etc. You then have resources, resources have availability. What you would do here is request it at which point an async process would get availability for each of the resources … if they fail then it would roll back.
You obviously can make this extremely unlikely to fail by issuing a query up front that the resources have availability.
in my system I’m dealing with dozens to few hundred resources and maybe few thousand bookings in a year. No scaling issue here.
However for the sake of understanding…
Scheduler, given OrderResourcesBooking (res1, res2, res3)
would ask each of those resources if they are available and if all are OK. proceed with booking?
If I get it right…
In this scenario, we introduce cross aggregate communication (via a service) but the state is stored in each resource.
I think Greg is saying “have a Schedule for, say, December” as opposed to having a single schedule aggregate for all time.
Querying up front means you can check the schedule for conflicts before submitting the command to minimize conflicts through within the aggregate.
In my view, having the schedule as its own aggregate makes sense since there are likely many concepts and rules for scheduling that are irrelevant to a “House”. Take a rule like “if you book Saturday, you MUST also book Sunday” [I ran into this one recently]. The “House” doesn’t care about this and introducing those concepts would muddy it’s world. It’s a scheduling concept and can be change often.
Further, if you wanted to introduce “wait lists” or other features, you wouldn’t be able to do that within a single house where you could easily do it on a Schedule.
Fwiw, you may see if the cleaning aspect should be separated for many of the same reasons.
HTH
Definitely schedule aggregate makes sense here. I would have hard time partitioning it by month but that’s a minor issue.
and indeed in my live system I did run into: if you book only one day - it costs different or a package booking: book 7 days - get special price (this is yet another aggregate i suppose )
Thanks guys.
Will share my developments when i have something.
If you have such low throughput requirements I would consider making a single schedule depending on how big it was. The trickier part (where you get into async processes etc is where you need to have a large number of operations). A good question to ask yourself might be “how would I model this in a document db”.