Hi,
I’m running a single node event store. I’ve got
- approximately 110.000.000 events
- distributed over 251 streams
- i’ve got the standard projections running
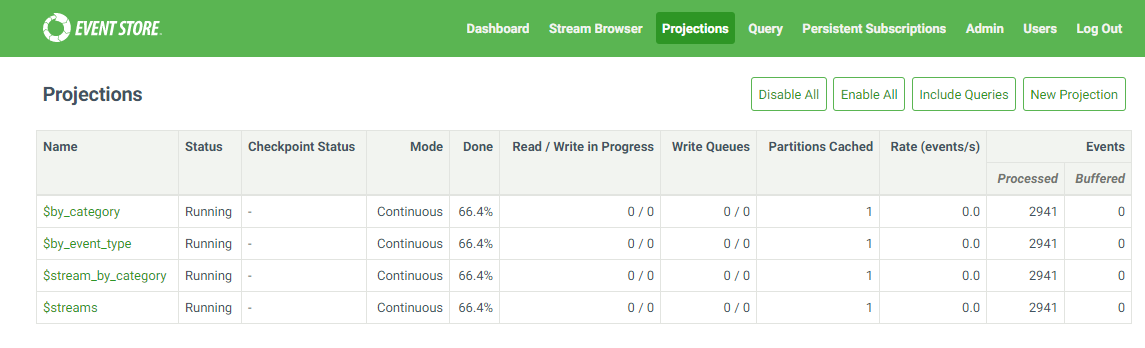
I’ve inserted the events while the projections were running. Appending the events was a lot quicker than the projections. So after all the events were appended the projections took about an hour to catch up. After that the projections showed 100% done in the UI.
Now when I shut down the eventstore and spin it back up again the projections reset to 65.8% after which it start climbing again to 100% in about an hour burning 40% CPU (I7 laptop) and reading 10MB/s from SSD. In the process the ‘processed events’ entry immediately goed to 2941 and it stays on that number until 100% is reached. Every time i restart the server this repeats. I haven’t appended any events after the initial import.
This feels kind of strange. If I had to guess i would think it has something to do with checkpoints being written by the projections. If I look at the $all stream the end of the stream consists only of $projections-$master en $stats entries. So perhaps it’s wading through all the ‘meta’ messages and it doesn’t write checkpoints for that?!
Is this explainable? Or a bug?
kind regards,
Arno den Uijl