Hi there,
We’ve got something we haven’t seen before on one of our ES clusters.
Verification of chunk #710-710 (chunk-000710.000004) failed, terminating server…
EventStore.Core.Exceptions.HashValidationException: Exception of type ‘EventStore.Core.Exceptions.HashValidationException’ was thrown.
at EventStore.Core.TransactionLog.Chunks.TFChunk.TFChunk.VerifyFileHash () [0x0010d] in :0
at EventStore.Core.TransactionLog.Chunks.TFChunkDb+c__AnonStorey0.<>m__0 (System.Object _) [0x0001e] in :0
It looks like these fatal logs started a few days ago;
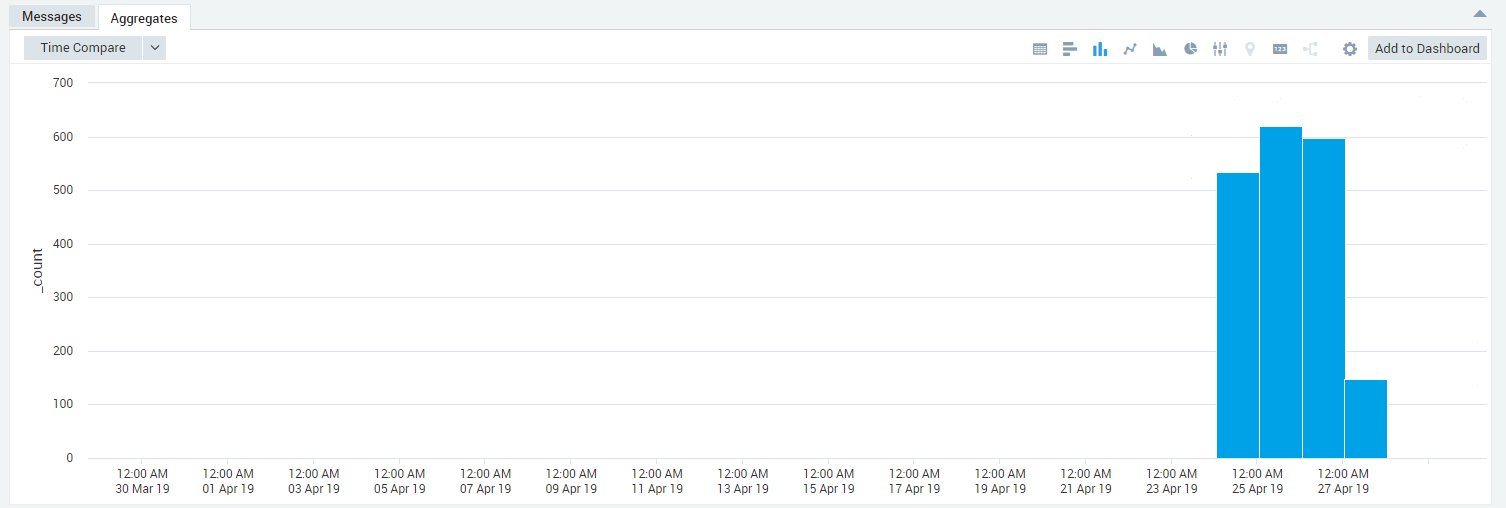
Not sure why it’s only affecting client apps now (clients complaining when the ES connection is dropped) but that’s beside the point - clients are recovering once the ES cluster is back healthy.
On the face of it the error message seems concerning, especially since it has caused two master elections in a few hours.
Interestingly the two master elections today means the original is now back as master. And looking at what’s changed on the cluster (which has otherwise been stable for the past 30 days), the appearance of fatal logs correlates with what appears to be a change to the cluster configuration - looks like a NPC was added on the 24th at around the same hour… The new master at that time was one promoted from one of the slaves so I’m confused why chunk verification has only started failing now.

So, questions;
- Is it bad that we’re back on the original master? Presumably the problem is still there and I’ll get another blip in a few hours.
- What is the chunk verification process? Does it run in the background? Does it run on all nodes or only the master? Am I seeing another master election after a few hours because chunk verification took that long to reach the bad chunk?
- How do I fix this? Should I shoot the master instance, force a new instance to come up and hope the backup chunk files aren’t corrupted?
- My main concern is whether the backup chunk files could have the same data corruption. If the backup chunk files have the same error, should I expect to see a delay of some hours before the chunk verification background process reaches the bad chunk and kills the ES process?
I’ve contacted GetEventStore support but there may be others out there who know answers to my questions. 
cheers,
Justin


