Hello,
I’m trying to implement the CQRS pattern using EventStoreDB.
My idea is to use Catch-Up subscriptions in order to project received events and store the read model in a MongoDB instance.
Let’s imagine this (common) scenario:
There are four active clients (A, B, C, D) subscribed to the same Stream “X”. When an event is appended to Stream “X”, all the subscribed clients receive a notification, and try to “create/update” the read model, potentially causing concurrency issues.
A similar use case is when multiple replicas of a client are available at the same time (ex. a microservice deployed and scaled out on a K8 cluster)
Is there a suggested way to handle this kind of scenario in the context of EventStoreDB, or is it up to the client logic to handle the concurrency complexity?
Thank you
Usually there is 1 active process with the catch-up subscription doing update to your read model.
And eventually a second one on stand-by if that first process should stop unexpectedly
When that becomes too slow , you can have multiple processes and partition them in such a way that they would handle a specific set of documents on the same target store.
(edited for typos)
1 Like
This means that:
There’s no way to scale out consumers by using Catch Up subscriptions. You must have just one active consumer and set up a strategy to replace it “when things are going to fail”. I’m thinking about a mechanism based on some metrics or on a health check. Anyway, it seems to me that this strategy introduces some extra complexity. Maybe the Catch-Up subscriptions are not well suited for this specific use case.
This consideration takes me to your second suggestion, which is to “Partition consumers”. In this case, I should switch from the Catch-Up subscriptions to the Persistent Subscriptions.
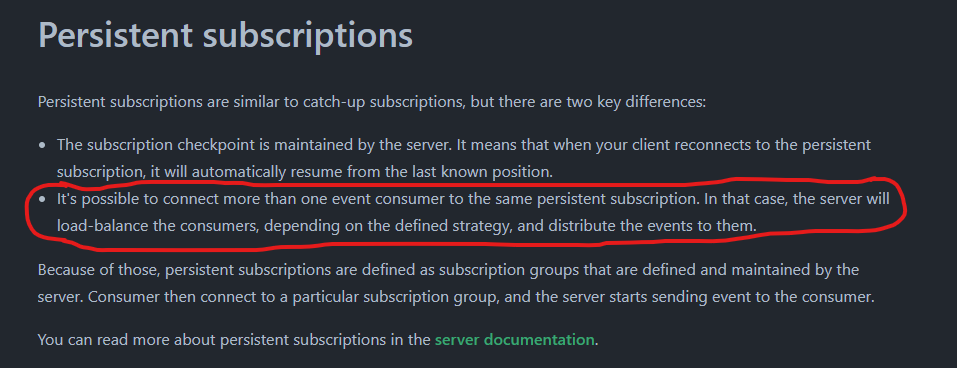
Effectively, looking at the Documentation, I read:
Finally, we could say that:
- If the specific use case requires the need to scale out the consumers, it would be better to rely on Persistent Subscriptions in order to leverage the provided “Consumers Load Balancing”
- If the specific use case doesn’t require scaling out consumers, it would be better to rely on the “Catch-Up subscriptions” and set up a basic mechanism to replace the “Consumer Single Instance” when it fails.
Do you agree with these considerations?
Thank you
To build read model , catch-up is the way the go.
Persistent subscription are Competing consumers , and ordering is not guaranteed.
You can go a long way to build your read models with a single subscriptions before having to think about any partitioning srategy.
And yes, do measure the gap / how fast you can go
as for a scd process ready for high availability , indeed monitoring. Which should be in place anyway.
1 Like
Ok, I got the point.
Thank you for the explanation!