Hello,
A best practice when adopting microservice architecture is segregating data using the “One Database per Microservice” strategy. This pattern generally has some advantages (no single point of failure, improved scalability) and some drawbacks (higher costs, more infrastructure to maintain).
Using EventStoreDB, it seems to me that this approach also has another very important implication:
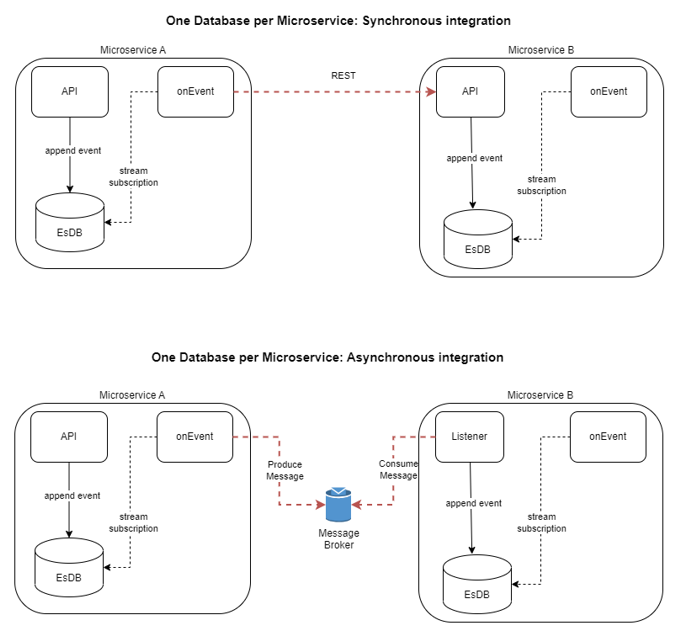
Segregating the db instance you can’t rely on the provided “subscriptions mechanism” to enable communication between microservices.
This means that if you want to go with the “One Database per Microservice” and EventStoreDB, you must implement integration logic into private subscriptions.
For example:
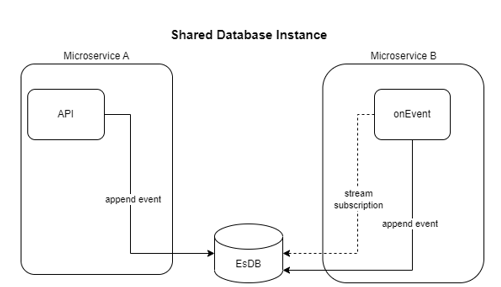
Instead, by adopting the “Shared DB instance” strategy, we could rely on the internal subscription mechanism also to implement microservices intercommunication.
For example:
Said that:
- Is there a suggested approach using “EventStoreDB”?
- Supposing to choose the “One database per microservice” strategy: which type of subscription one should use to implement the “integration” logic? “Catch up” or “Persistent subscriptions”? I would say the latter, because of the “automatic checkpointing” and “at-least-once” delivery provided out of the box.
Thank you