Hello dear community,
I am pretty new to EventStoreDB, and I am excited to learn more about it. In fact, I am proud to cover EventStore in my Master thesis, for which I am going to implement a PoC.
The proof of concept covers, among others, how event sourcing and CQRS can be applied for (an event-driven) microservices architecture.
Let’s suppose we have a Write Microservice and a Read Microservice. The Write Microservice uses an instance of EventStoreDB. The Read Microservice uses an instance of MongoDB. Now, the main question is: What is the optimal approach for projecting events from the Write Microservice to the Read Microservice. For me, there are several options, each with different trade-offs:
-
Message Queues: In literature, you often read about message queues that transport events from the write side to the read side. However, I also read about the out-of-order problem, especially when using multiple instances of the read microservices.
-
CatchUp Subscriptions: The Read Microservice could use a catch-up subscription to project the data from the event store to the read model. However, what if I use several instances of the read microservice (sharing the same database)? The other read microservices would also create their own catch-up subscription, resulting in a lot of network traffic. Furthermore, the out-of-order processing problem also occurs here…
-
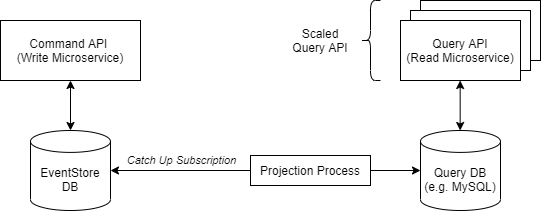
A separate “projection process” or microservice (currently my favorite): In this approach, there is another simple process in between the write and read microservice; let’s call it the “projector”. The projector runs one catch-up subscription and saves the position of the last processed event. The projector populates the query database. The main advantage that I see with this approach is that we now can scale the read microservice without any problems, as the projection logic is not part of the read microservice anymore.
-
Persistence Subscriptions: Currently not an option, as events can get out-of-order.
What do you think about these options? Furthermore, any best practices on projecting the read model so that it allows scaling of the read microservice?
Thanks in advance for any answer.
Best regards
Domenic