For anyone using Catchup subscriptions, how do you detect that your catchup subscriptinos are still running?
I have had a hunt through the documentation as well as check through the various UI tabs and can’t see anything specific.
We might have a few situations on our own systems where a catchup might be better suited than persistent, but we need to be sure that the events are still being delivered.
Thanks in advance.
Steven
We have two health checks running.
One that polls internal ES-projections, and restarts them on failure (they stop on disk timeout, leading to hard to diagnose errors for our support)
One that checks last known position in ES, then polls a few select read stores (relational) and verifies checkpoints.
/Peter
Peter,
The catchup wouldn’t run as a projection, is that correct?
Just so I understand this fully, you are checking for the things around the catchup failing, rather than being able to identify the catchup has stopped itself?
That is correct, but the SubscriptionDropped event seems pretty reliable. (have had a few incidents but a long time ago) and we have a lot of code around reconnecting a stopped catchup. This has been a problematic area in general, the eventing model, batching writes, unclear reason-for disconnect etc. Can’t count the number of rewrites I’ve done to avoid spaghetti code around this…
I’ve seen some examples that just have KeepReconnecting and KeepRetrying for subscriptions, but I haven’t found that reliable enough. If a connection gets a heartbeat timeout, the subscriptions is lost and will have to be restarted.
/Peter
Interesting to know.
Ideally, we would want someting on the UI to show us Catchups in progress (maybe even a state of whether it’s “catching up” or “live”)
We have a public repository for a service which helps make persistent subscription easier to run:
https://github.com/vmeretail/subscriptionservice
Our next release will include catchup subscriptions, so trying to get a handle of what users would actually want to be able to do.
From what you are telling me, having an auto restart would be very useful (i.e. when we detect SubscriptinoDropped, we would call SubscribeToStreamFrom again)
For performance, a batched interface is pretty important. Max batchsize, max latency.
We were planning on on allow the user to pass in CatchUpSubscriptionSettings, as well as an “Automatically restart” option.
Anything else that would be usefull?
Do you run the catchup code from specific hosting process?
This is for your out-of-process publisher right? Haven’t really looked into it, and not sure if it adds anything for us.
Our projections are hosted in windows services (no http endpoints), and asp.net core BackgroundServices. (have mixed feeling about this. I like that they run ‘close’ to where they are consumed, oth it feels wrong they have to be always running)
/Peter
Peter,
Thanks for the information. very useful.
Steven
we run heartbeats to keep track of both uptime for catchup subscriptions and end-end latency.
a heartbeat generator app has a pacemaker which calls each API (we have several) once per minute.
everything goes through the normal plumbing; the API generates a heartbeat command, an aggregate is read from its stream, a heartbeat event is emitted.
all downstream projectors subscribe to the $ce-heartbeat stream and apply heartbeats to their relevant readstore.
a separate heartbeat monitor process polls each readstore every minute and asserts the latest heartbeat is not too stale - fires alerts on failure
and this is the output - with alerting when thresholds are exceeded.
you can see 4 APIs receiving heartbeats (the ordering is a bit out, the first one should be “heartbeats generated from generator to APIs”)
then we happen to have 4 readstores though these weren’t always the same number as APIs. And you can see there’s actually a fifth projector which writes to an external system
the key graph/SLO is time from generator to database. That’s our eventual consistency window.
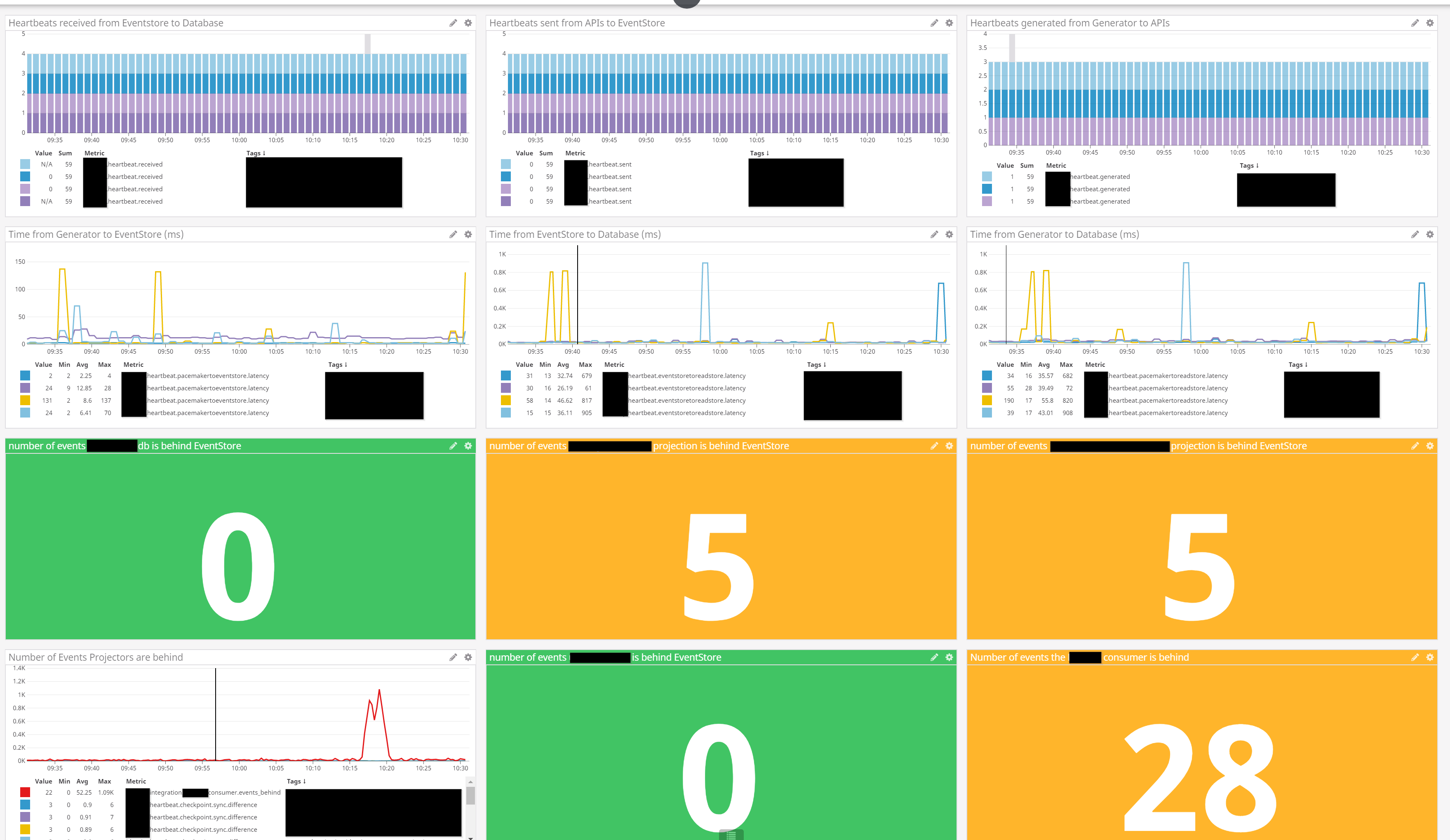
hope that’s useful. 
Hi Justin,
Are you planning to open source this, as it would be really useful to see how you’ve done things.
Thanks,
Sean.
My thoughts exactly Sean…
Assuming not, this is something we could probably spike in a day and OSS. I hear there are some people coming up on some unexpected availability.
I will join
Are you planning to open source this, as it would be really useful to see how you’ve done things.
I’d love to, unfortunately it’s part of a monorepo so slightly difficult to do without some work.
Assuming James Geall still works at GetEventStore I’ve sent him an email to discuss offline - there may be something we can do to get partway there.